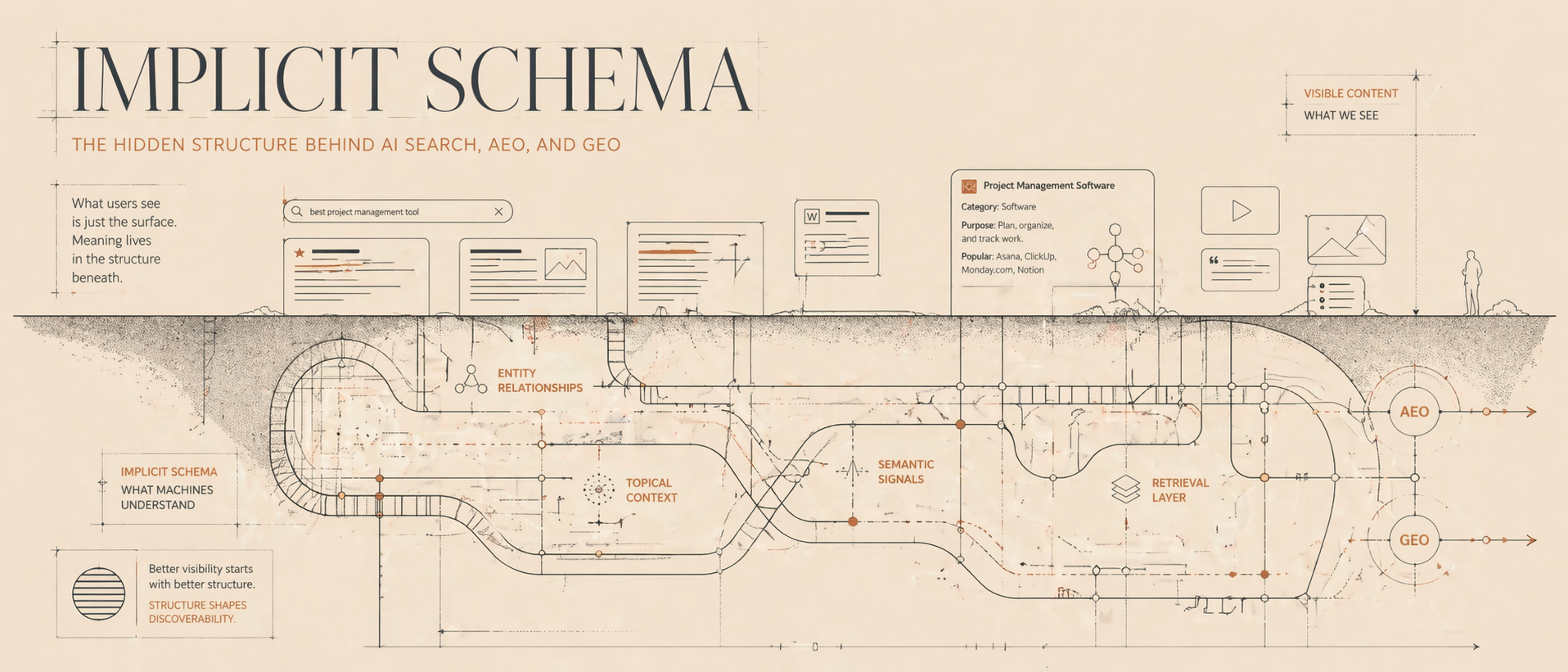
Implicit Schema: The Fastest AEO Win Nobody's Taking
Structure is schema. Here is the checklist to help AI cite your page.
Last week we covered fan-out. One question in, nine searches out, one answer back.
If you don't remember it you can find it here
This week is the part that explains how to write content and why.
When most people hear "schema" and think JSON-LD. They think structured data markup. They think "I need a developer for this."
And yes I used to think the same. But you don't.
LLMs can read structure from the way you write. Your heading hierarchy, your paragraph breaks, your tables, your Q&A blocks. All of that functions as schema for AI systems.
You could even say schema = text structure.
Specifically it is called implicit schema. And it's probably the most underrated concept in AEO right now.
Why format matters as much as substance
There is a chart that has been circulating in the AEO community comparing what ChatGPT prefers to cite versus what Google traditionally rewards.
And to me the numbers are wild.
SE Ranking analyzed 129,000 domains and 216,000+ pages. Pages with proper H1/H2/H3 hierarchy get significantly more citations. Content with consistent heading levels is 40% more likely to be cited.
Those are quite big differences. ChatGPT is almost twice as sensitive to heading structure as Google is.
And here is the thing that makes this so actionable. You don't need to add JSON-LD to get most of these benefits. The heading structure, the lists, the Q&A format, the tables: those are things you control in your CMS right now. Today. Without filing a dev ticket.
How LLMs actually read your page
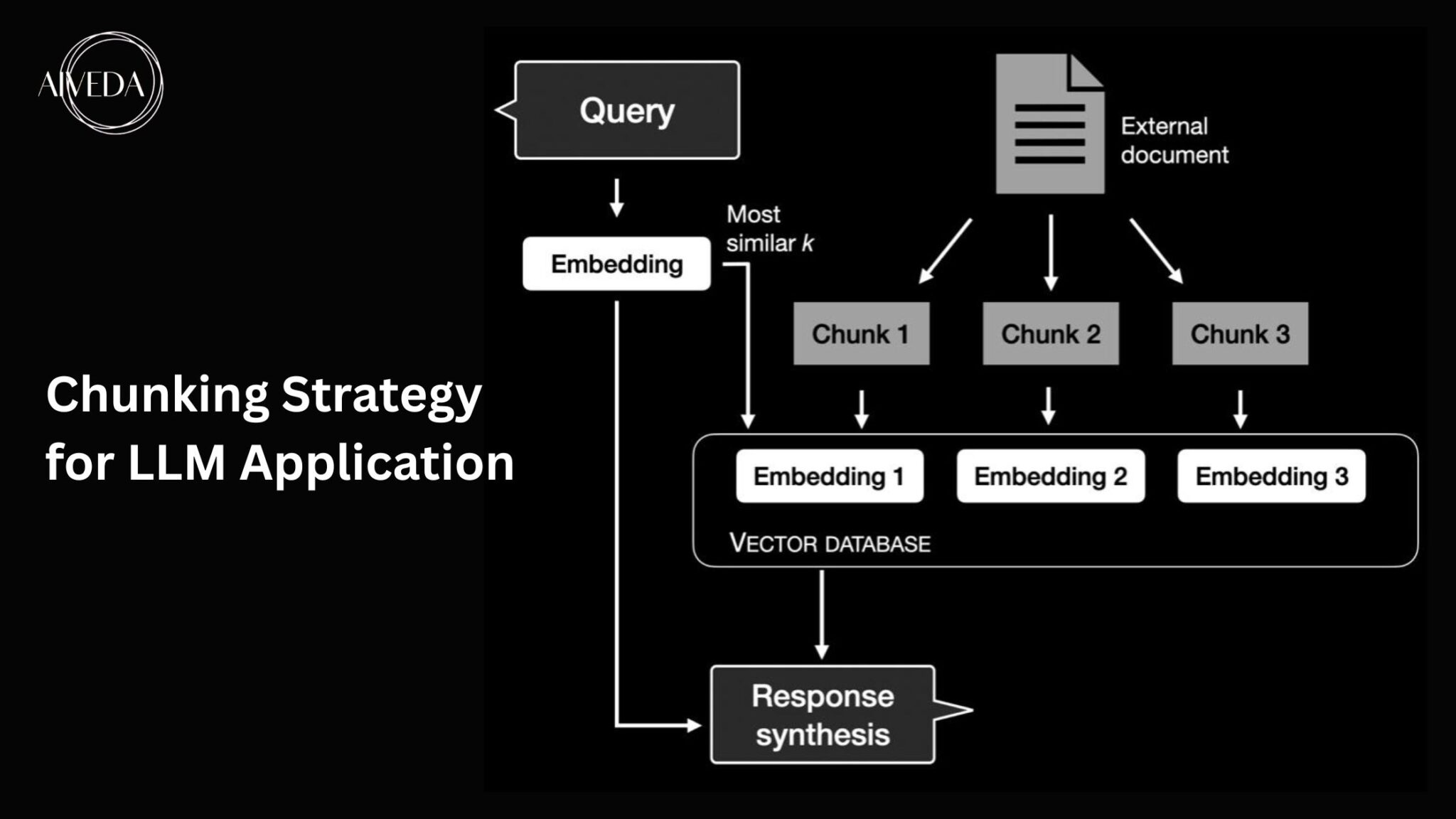
To understand why structure matters so much, you need to understand how LLMs "consume" content. It's a bit different from how Google does it.
Google reads your whole page and evaluates it as a unit. Relevance, authority, backlinks, technical signals.
LLMs don't work like that.
They read your page in chunks. A paragraph here. A table there. A Q&A block somewhere in the middle.
When an LLM is building an answer, it's scanning across dozens of pages and pulling the best chunk from each one.
So a 3,000-word article with great information buried in long unstructured paragraphs might be skipped by LLMs. And this is not because the content is bad, but because it couldn't extract the right information easily.
A shorter page with clear sections and self-contained paragraphs gets the page quoted. Each chunk has to stand on its own.
This is the main difference from how you would write for humans. Now you are also writing for a retrieval system that samples your page at specific points and decides which fragments are worth quoting.
The implicit schema checklist
Below I'm going to show you how to exactly structure your content so that LLMs can easily extract it and cite your page. Each item connects a format choice to a specific extraction mechanic.
1. One H1 per page. Make it the question or entity you want to own.
LLMs use your H1 to determine what the page is about. If you have two H1s, the model has to guess which one matters. And this is not good.
If your H1 is vague ("Our Solutions" instead of "Best CRM Software for Small Teams 2026"), the model might not even connect your page to the right fan-out query.
One H1. Specific. Matches the query you want to win.
Do you remember? When you ask AI a question it runs a set of sub questions that are related to your initial question. This is called query fan-out. There is another blog article about this topic here
2. Use H2s and H3s as chunk boundaries.
LLMs treat heading transitions as natural break points. When the model extracts a chunk, it often grabs everything between two headings. That means each H2 section needs to be a complete, self-contained answer.
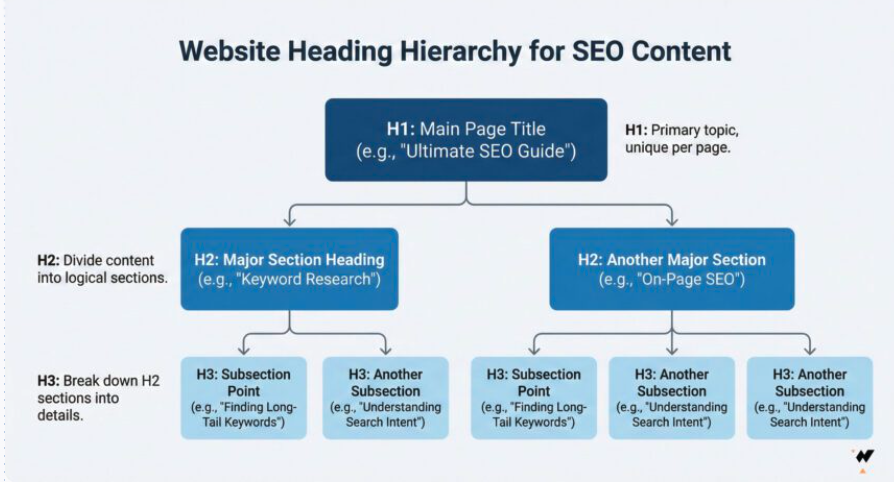
Test: can someone read just one H2 section and understand the answer without reading anything else on the page? If yes, the model can extract it. If no you have to rewrite it.
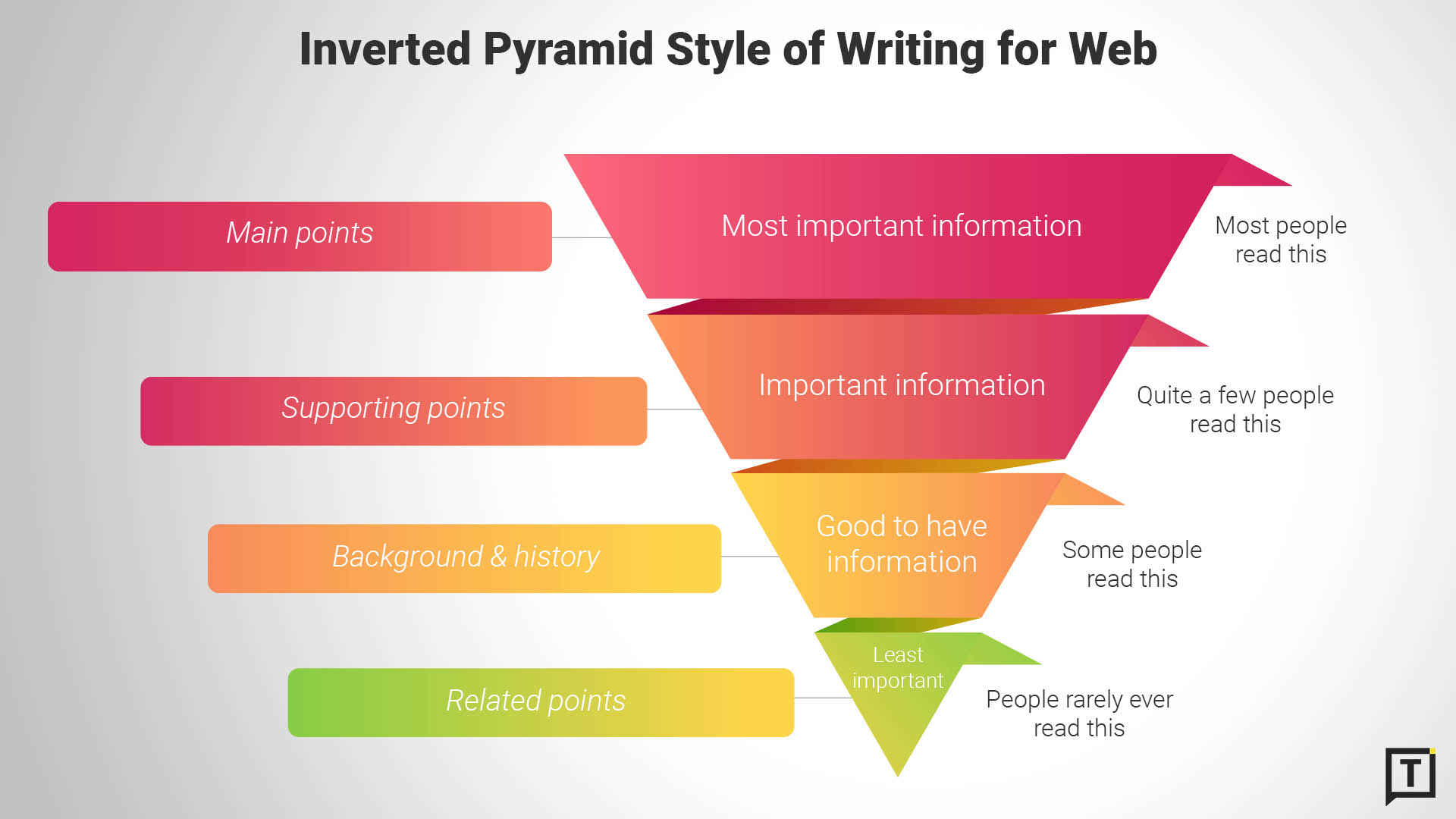
3. Start each section with the answer, not the context.
LLMs favor content that leads with the conclusion. "The best CRM for small teams is HubSpot because..." gets extracted. "When evaluating CRM options, it's important to consider several factors..." gets skipped.
Answer first. Context second. Always.
4. Use HTML tables for comparisons and structured data.
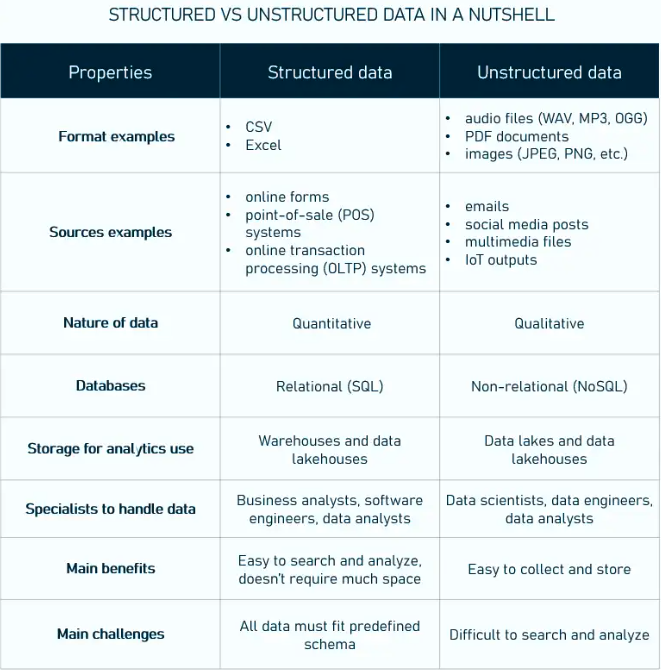
Tables are significantly more likely to get cited by ChatGPT than by Google Search. The reason: tables compress a lot of information into a format the model can parse instantly. Features, pricing, pros/cons, comparisons: if it can be a table, make it a table.
And one thing that trips people up: if you use image-only tables (screenshots of spreadsheets, infographics with data baked into the image), LLMs can't read them. Always pair visual tables with a real HTML or markdown table underneath.
5. Add Q&A blocks, even without FAQ schema.
LLMs are trained to recognize the question - answer pattern. A clear "Q: How much does X cost?" followed by "A: Plans start at $29/month" is extraction gold. The model can lift that pair cleanly and drop it straight into an answer.
And here it gets interesting:
Most people think FAQs get cited by LLMs because FAQ schema is important.
No, that's backwards.
FAQs get cited because LLMs are trained to recognize and extract question-answer patterns. The format is the signal. The schema just makes it more explicit.
LLMs learned this from training data long before FAQ markup existed: forums, support docs, Reddit threads, interview transcripts. Billions of Q&A pairs. The model knows exactly what to do when it sees a question followed by a direct answer: extract the pair, match it to a query, quote it.
You can add formal FAQ schema if you want. But even without the markup, Q&A formatted content gets extracted because the pattern itself is the signal.
6. Write self-contained paragraphs.
Each paragraph should make one point, completely. No "as mentioned above." No "see the section below for details." The model might only see this paragraph. If it depends on another paragraph to make sense, rewrite it so it stands alone.
Short paragraphs win. 2-3 sentences. One idea per paragraph. That's what LLM models love to quote.
7. Add "who it's for / who it's not for" sections.
This is one of the highest-value structural additions for commercial content. When an LLM is answering a question like "best project management tool for freelancers," it's actively looking for content that self-segments.
"Best for: teams of 1-5 who need simple task tracking. Not ideal for: enterprise teams needing advanced reporting."
That block answers a fan-out sub-query directly. And it gives the model permission to recommend you for the right audience, which increases citation probability for long-tail queries.
8. Use summaries at the top of sections.
A 2-3 sentence summary at the top of a long section works like a thesis statement for the model. It tells the LLM "here's the core point" before the supporting details. If the model is in a hurry (and it always is), it can grab the summary and move on.
Think of it as writing the chunk you want the AI to quote.
The before and after
I also would like to show you what it looks like in practice.
Before (typical SEO page):
A 2,500-word article about project management tools. One H1 that says "Project Management Software." Five long paragraphs of introduction before any tool is mentioned. Comparison data embedded in an infographic image. No Q&A section. No "best for" segments. Every paragraph references other paragraphs.
The model lands on this page, scans it, finds no clean chunk to extract, moves on.
After (implicit schema applied):
Same content, restructured. H1: "Best Project Management Tools for Remote Teams 2026." Each tool gets its own H2 section. Each section opens with a 2-sentence summary. A comparison table in HTML covers pricing, features, team size. Q&A block at the bottom: "Which tool is best for freelancers?" "Which integrates with Slack?" "Who it's for / who it's not for" under each tool.
The model lands on this page, finds 8 extractable chunks, cites 3 of them in one answer.
Same content. Different structure. Completely different AI visibility.
The bottom line
Implicit schema is a super fast AEO/GEO win most teams aren't taking.
You don't need JSON-LD. You don't need a developer. You need to restructure your existing content so every section stands on its own, every answer leads with the conclusion, and every comparison lives in a real table.
Go pick one page. Run through the checklist. Restructure it. Then ask ChatGPT a question that page should answer and see if you get cited.
That's the test. And it takes an afternoon.
Up next
Next email: why the AI cited your competitor and not you. We'll get into how citations actually work, where offsite authority matters more than you think, and why building presence on third-party platforms might be the highest-ROI AEO move you're not making.
Talk soon.
End of Lesson 3. Next week: why the AI cited your competitor (and what they did to earn it).
Here are also the previous lessons:
- Lesson 1: What is AI Search
- Lesson 2: All about Query Fan-Out
This Week's Signals
Big week. Three findings that close the loop on the AEO business case.
Gemini 3 reshuffled the citation layer. SE Ranking tracked 97,574 domains post-rollout. 42.4% of previously cited sources vanished. 51.7% of citations went to new domains. And only 19% of AIO sources overlap with top-10 organic results. Ranking #1 in Google gets you cited in AIO just 33% of the time. Pull your baseline again. Everything before April 17 is stale.
AI traffic now converts 42% better than paid search. Adobe's Q1 2026 report: AI-sourced retail traffic up 393% YoY. Conversion rate 42% higher than non-AI. One year ago it was 38% worse. 80-point swing in 12 months. Revenue per visit 37% higher. Users arrive pre-qualified. The CFO conversation just changed.
AEO is forking into two disciplines. Addy Osmani (Google Cloud AI) published the first operational framework for Agentic Engine Optimization, optimizing for AI agents, not answer engines. Different mechanics: single HTTP fetch, HTML stripped, 100K-200K token budget. Bloated content gets silently dropped. Two lanes now: answer surfaces and agents. Pick one to specialize in.
Ask Maps returns one recommendation. Not a list. One. The sourcing stack: GBP attributes, Maps reviews, your site, plus trusted external directories. Local AEO just compressed to winner-take-most.
Sources
Gemini 3 + AIO Citation Reshuffle: Google Blog · TechBuzz · SE Ranking analysis
AI Traffic Conversion Data: Adobe Q1 2026 Report · Search Engine Land · TechCrunch
Agentic Engine Optimization: Addy Osmani · Search Engine Land
Google Ask Maps: Google Blog · Search Engine Land